Author: Omar Trejo Navarro
Apart from the fact that R is an interpreted language, which can pretty much confuse people used to compiled languages, most programmers would agree that manipulating objects in R can sometimes be a nightmare. This has to do with two significant features of R that make OOP manipulation highly efficient:
- R has several object models unlike Java, Python and others, which have only one
- R implements parametric polymorphism, while other OOP (Object-oriented programming) languages generally implement polymorphism from inside an object
Let’s look at these two in a bit more detail.
Various object models
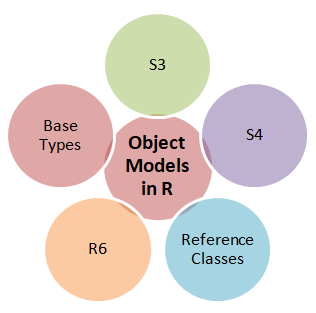
Working with OOP in R is different from what you may see in other languages such as Python, Java, C++, etc. These languages have a single object model. However, R has various object models, meaning that it lets us implement object-oriented systems in various ways. Specifically, R has the following object models:
- S3
- S4
- Reference Classes
- R6
- Base Types
In this article, we will look at S3, S4, and R6, since these are the most-used object models in R, but more on that later. Let’s first understand what parametric polymorphism is.
Parametric polymorphism
R implements parametric polymorphism, which implies that methods in R belong to functions, not classes. Parametric polymorphism basically lets you define a generic method or function for types of objects you haven’t yet defined and may never do. This means that you can use the same name for several functions with different sets of arguments and from various classes.
R’s method calls look just like function calls and R must have a mechanism to know which names require simple function calls and which names require method calls. This mechanism is called generics. Generics allow you to register certain names to be treated as methods in R, and they act as dispatchers. When these registered generic functions are called, R looks into a chain of attributes in the object being passed in the call in order to look for functions that match the method call for that object’s type. If it finds a function, it will call it.
You may have noted that the plot() and summary() functions in R may return different results depending on the objects being passed to them (e.g. a data frame or a linear model instance). This is because they are generic functions that implement polymorphism. This way of working provides simple interfaces for users and makes their tasks much simpler. For instance, if you are exploring a new package and you get some kind of result at some point derived from the package, try calling plot(result), and you may be surprised to get some kind of plot that makes sense. This is not common in other OOP languages.
Now that we have a basic idea of what parametric polymorphism is and how it sets R apart from other OOP languages, let’s look at S3, S4, and R6.
R’s most common object models
The S3 object model of R owes its roots to the object model of the S language, the predecessor of R. S’s object model evolved over time, and its third version introduced class attributes, which paved the way for S3. S3 is the fundamental object model of R, and many of R’s own built-in classes are of the S3 type.
Being the least formal object model in R, S3 does lack in some key respects:
- It has no formal class definitions, thereby leaving no scope for inheritance or encapsulation
- Polymorphism can only be implemented through generics
Nevertheless, it makes up for what it lacks in by providing quite a lot of flexibility to the programmers. In the words of Hadley Wickham, “S3 has a certain elegance in its minimalism: you can’t take away any part of it and still have a useful object-oriented system“.
However, one of the biggest demerits of S3 is that it doesn’t provide the required safety; it is very easy to create a class in S3, but it may lead to very confusing and hard-to-debug code if not used with utmost care. For example, a programmer could misspell a function and S3 would raise no issues. This is why S4 came into the picture, developed with the goal of adding safety. It keeps the code safe but, on the flip side, introduces a lot of verbosity to the code. It implements most features of modern object-oriented programming languages:
- Formal class definitions
- Inheritance
- Polymorphism (parametric)
- Encapsulation
In reality, S3 and S4 are really just ways to implement polymorphism for static functions. The R6 package provides a type of class that is similar to R’s Reference Classes, but it is more efficient and doesn’t depend on S4 classes and the methods package, as Reference Classes do.
When Reference Classes were introduced, some users called the new class system R5, following the names of R’s existing class systems S3 and S4. Although Reference Classes are not actually called R5 nowadays, the name of this package and its classes follow the pattern. Despite being first released over 3 years ago, R6 isn’t widely known. However, it is widely used. For example, R6 is used within Shiny and to manage database connections in the dplyr package.
The decision of which object model to use eventually boils down to a trade-off between flexibility, formality and code cleanness.
R Programming by Example
R is a high-level statistical language and is widely used among statisticians and data miners to develop analytical applications. Given the obvious advantages that R brings to the table, it has become imperative for data scientists to learn the essentials of the language.
R Programming by Example is a hands-on guide that helps you develop a strong fundamental base in R by taking you through a series of illustrations and examples. Written by Omar Trejo Navarro, the book starts with the basic concepts and gradually progresses towards more advanced concepts to give you a holistic view of R. Omar is a well-respected data consultant with expertise in applied mathematics and economics.
If you are an aspiring data science professional or statistician and want to learn more about R programming in a practical and engaging manner, R Programming by Example is the book for you!